《深入理解Java虚拟机》Java线程与锁优化
words: 5.6k views: time: 20min线程是比进程更轻量级的调度执行单位,线程的引入可以把一个进程的资源分配和执行调度分开,各个线程既可以共享进程资源(内存资源、文件I/O等),又可以独立调度。
Java提供了在不同硬件和操作系统平台下对线程操作的统一处理,每个已经执行start()且还未结束的java.lang.Thread实例就代表了一个线程。
1. 线程
1.1. 线程实现
- 内核线程
内核线程(KLT)直接由操作系统内核支持,每个内核线程可以视为内核的一个分身。这种线程由内核来完成线程切换,内核通过调度器(Scheduler)对线程进程调度,并负责将线程的任务映射到各个处理器上。
程序一般不会直接使用内核线程,而是通过一种高级接口:轻量级进程(LWP),也就是我们通常意义上所讲的线程。每个轻量级进程都由一个内核线程支持,也就是1:1的关系。
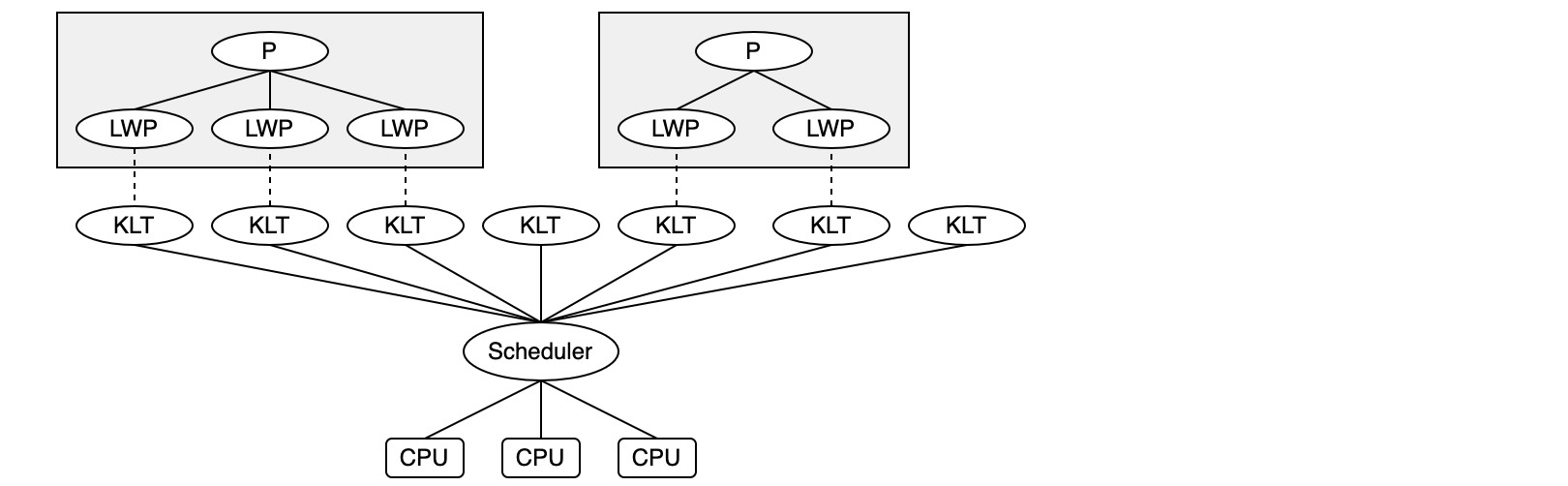
但是基于内核实现,各种线程操作,如创建、析构以及同步,都需要进行系统调用。而系统调用代价相对较高,需要在用户态和内核态之间来回切换。另外,由于每个轻量级进程都需要一个内核线程支持,因此一个系统能够支持的轻量级进程数量也是有限的。
- 用户线程
一般如果一个线程只要不是内核线程,那么就可以认为是用户线程,所以上面的LWP也属于用户线程。但严格意义上的用户线程是指完全建立在用户空间的线程库上,系统内核不感知线程的存在。这样线程的建立、同步、销毁及调度都在用户态完成,不需要内核介入,因此操作可以非常快速且低消耗,也可以支持更大规模的线程数量。

但用户线程没有内核支持,所有的线程操作都需要自己处理,因此在实现上相当困难。
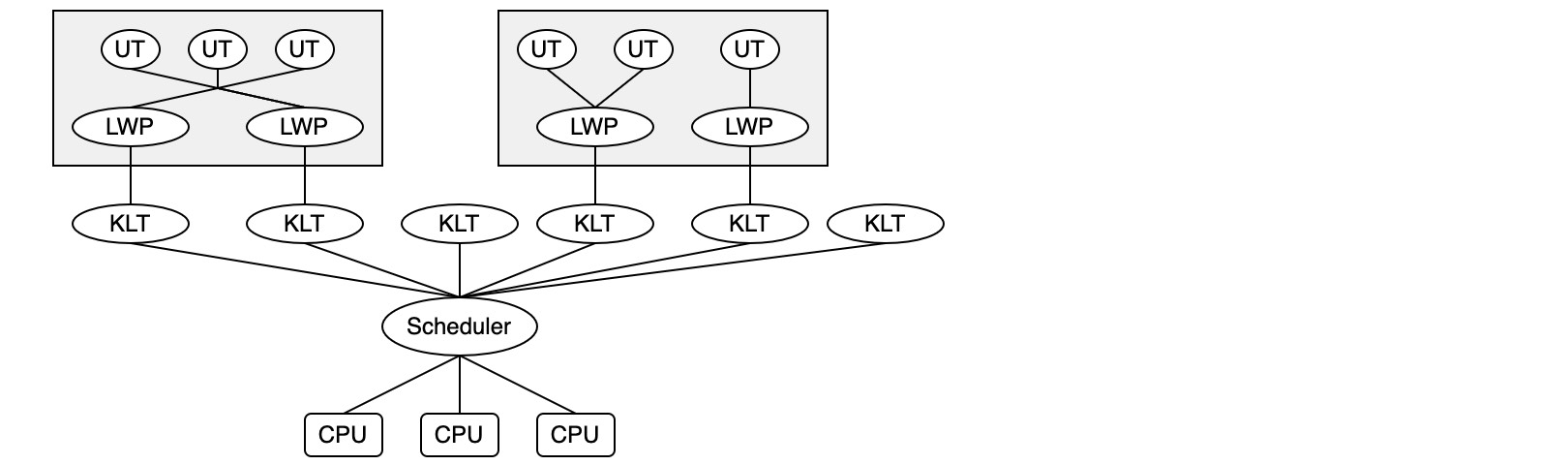
- 混合实现
混合实现下,既存在用户线程,也存在轻量级进程。线程还是完全建立在用户空间中,因此对于创建、切换、析构等操作依然廉价,并可以支持大规模的用户线程并发。而轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核线程提供的线程调度以及处理器映射处理。
- Java线程实现
Java在1.2之前,是基于称为绿色线程的用户线程来实现的,而在1.2之后,线程模型改为直接基于操作系统原生线程模型来实现。因此,操作系统支持怎样的线程模型,很大程度上就决定了Java虚拟机的线程实现。
由于Windows和Linux提供的线程模型都是1:1的内核线程模型,因此,Windows和Linux版的JDK都是使用的一对一的线程模型实现的,也就是一个Java线程映射到一个轻量级进程之上。
1.2. 线程调度
线程调度是指系统为线程分配处理器使用权的过程,主要有协同式调度和抢占式调度。
如果使用协同式调度,线程的执行时间由线程本身来控制,线程把自己的工作执行晚了之后,主动通知系统切换到另一个线程上。其好处是实现简单,而且由于线程要把自己的事情干完后才会进行线程切换,切换操作对于线程自己是可知的,所以不存在什么线程同步问题。但坏处也很明显,因为线程的执行时间不可控,如果一个线程一直阻塞也就一直不会通知系统进行线程切换。
如果使用抢占式,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定。这种方式下,线程的执行时间是系统可控的,也就不会出现一个线程导致整个进程阻塞的问题。
1.3. Java线程状态
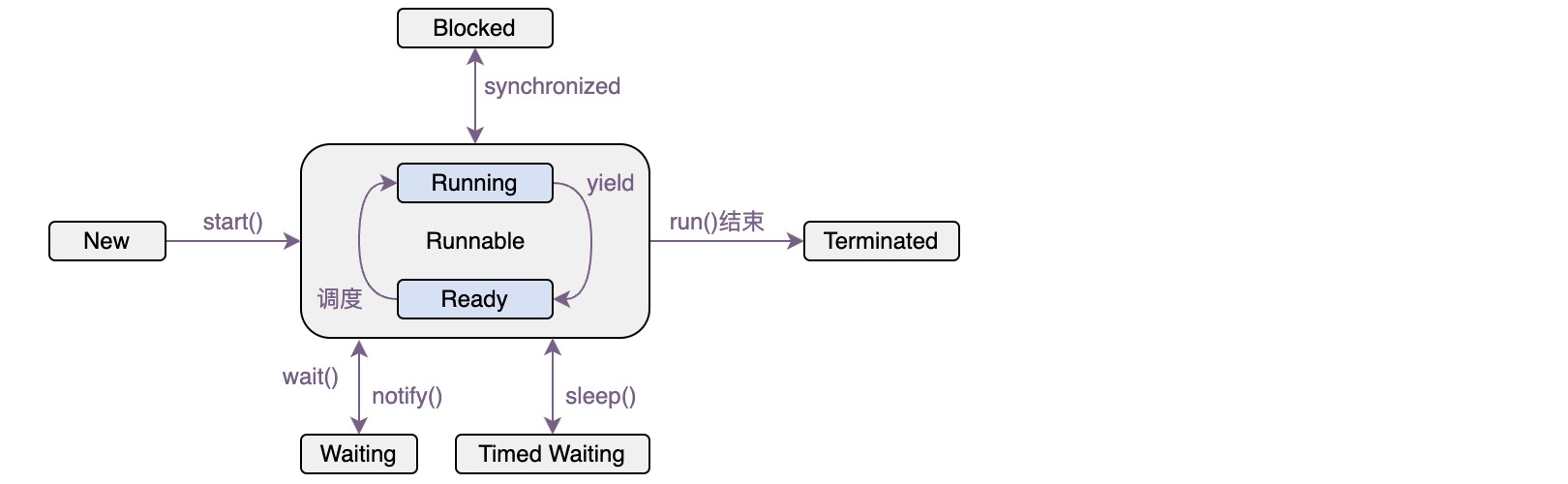
Java定义了5种线程状态,在任意一个时间点,一个线程只能处于一种状态
- 新建 New
即创建后尚未启动的线程,此时只是一个Java对象
- 运行 Runable
对应操作系统线程状态中的 Running 和 Ready,也就是线程可能正在执行,也可能正在等待分配CPU执行时间
- 无限期等待 Waiting
线程不会被分配CPU执行时间,需要其它线程显式地唤醒,使线程进入无限期等待的方法一般有Object.wait()、Thread.join()、LockSupport.park()
- 限期等待 Timed Waiting
同样不会被分配CPU执行时间,但不需要其它线程显式地唤醒,一定时间后由系统自动唤醒,使线程进入限期等待的方法一般有Thread.sleep()、Object.wait()、Thread.join()、LockSupport.parkNanos()、LockSupport.parkUntil()
- 阻塞 Blocked
线程阻塞与等待的区别是,阻塞状态是在等待一个排他锁,直到另一个线程释放这个锁,而等待是等待一段时间,或者是等待唤醒动作的发生,当线程进入同步块时就进入阻塞状态。
- 结束 Terminated
已执行结束的线程
对于上面5种状态,可以画出其状态转换图如下:
2. 锁(synchronized)
synchronized是Java中用来实现线程同步操作的关键字,由JVM实现,这样可以使得应用开发中对于线程同步的操作非常简洁,这里简单讨论一下其实现机制。
2.1. Monitor
JVM中的synchronized是基于进入(monitorenter)和退出(monitorexit)Monitor对象来实现的,在涉及同步的对象头信息中会保存指向Monitor的指针。monitorenter指令会在编译后插入到同步代码块的开始位置,而monitorexit则插入到方法结束处和异常处。任何对象都有一个Monitor与之关联,当Monitor被持有后,它将处于锁定状态。
在hotSpot中,Monitor由ObjectMonitor实现,其主要结构如下:
1 | ObjectMonitor() { |
owner:初始为NULL,当被线程占有时,owner标记为该线程的唯一标识。当线程释放时,owner又恢复为NULL。owner是一个临界资源,通过CAS操作来保证其线程安全;
_cxq:竞争队列,所有请求锁的线程首先会被放到该队列中(单向链表)。
_cxq也是一个临界资源,同样通过CAS操作来修改,比如compareAndSet(node.next, newThread),因此,_cxq是一个后进先出的stack;_EntryList:监控区,锁已被其他线程获取,期待获取锁的线程就进入Monitor对象的监控区;
_WaitSet:待授权区,曾经获取到锁,但是调用了wait方法,线程进入待授权区;
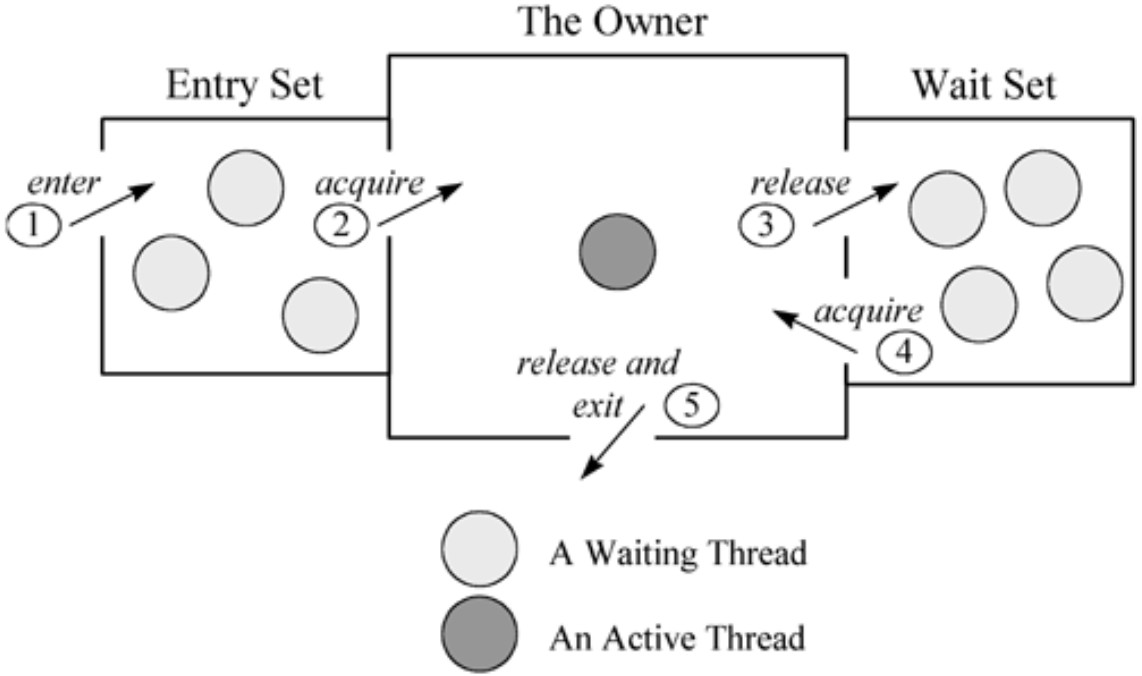
_WaitSet区域的线程收到Notify/notifyAll通知时,会进入_EntryList区域。即通过object获得内置锁objectMonitor,然后调用其notify方法,将_waitset结点移出等待链表,并置于_EntrySet,等待获取锁。
1 | // 1.调用ObjectSynchronizer::notify方法 |
当前拥有锁的线程释放锁时,处于_EntryList区域的线程都会抢占该锁,但是只能有一个Thread抢占成功,而其它线程依然在_EntryList中等待下次抢占锁的机会。也是通过object获得内置锁objectMonitor,并通过内置锁将Thread封装成OjectWaiter,然后调用addWaiter将它插入_waitSet中,最后释放锁。
1 | // 1.调用ObjectSynchronizer::wait方法 |
2.2 Mutex Lock
Monitor本质是基于底层操作系统的Mutex Lock(互斥锁)来实现的,每个对象都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
互斥锁:用于保护临界区,确保同一时间只有一个线程访问数据。对共享资源的访问,先对互斥量进行加锁,如果互斥量已经上锁,调用线程会阻塞,直到互斥量被解锁。在完成了对共享资源的访问后,要对互斥量进行解锁。
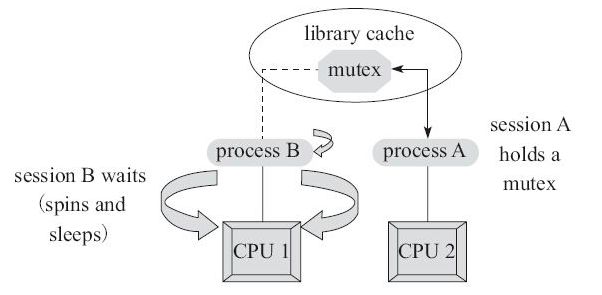
- 申请mutex
- 如果成功,则持有该mutex
- 如果失败,则进行spin自旋,spin的过程就是在线等待mutex,不断发起mutex gets,直到获得mutex或者达到spin_count限制为止
- 依据工作模式的不同选择yiled还是sleep
- 若达到sleep限制或者被主动唤醒或者完成yield,则重复1~4步,直到获得为止
3. 锁优化
由于Java线程是映射到操作系统的原生线程之上,如果要阻塞或唤醒一条线程,都需要操作系统来帮忙完成,这就需要从用户态转换到内核态中,而状态转换需要耗费很多的处理器时间。所以synchronized是Java语言中的一个重量级操作。因此,在JDK1.6中,虚拟机进行了一些优化,譬如在通知操作系统阻塞线程之前加入一段自旋等待过程,目的就是避免频繁地切入到内核态。
3.1. 锁消除
锁消除是指虚拟机即时编译器在运行时,检测到在一些同步代码上不可能存在共享数据的锁竞争。其检测依据主要来源于逃逸分析的支持,如果判断一段代码中,堆上的所有数据都不会逃逸出去而被其它线程访问到,那就可以把它们当做栈上数据对待,认为是线程私有的,也就无须加锁操作了。
很多情况下,一些同步操作并不是开发人员自己加入的,而是本身就存在于很多Api的调用中,比如StringBuffer。
3.2. 锁粗化
理论上,在开发中应该将同步操作的范围限制成越小越好,只在必要的共享数据操作时才进行同步,这样如果存在锁竞争,其他等待的线程能够尽快获取到锁。
但如果一系列的操作频繁地对同一个对象反复的加锁和解锁,甚至在循环体中进行,那么即使没有线程竞争,就加锁解锁操作本身也会造成不小的消耗。因此,如果虚拟机检测到有这样一些列零碎的同步操作,将会把同步范围粗化到整个操作的外围。
3.3. 自旋锁
考虑到很多共享数据上的锁定状态只会持续很短时间,而为了这段很短的锁定时间去挂起和恢复线程并不值得。如果存在多个处理器,能让两个或以上的线程同时执行,那么可以让后请求锁的线程自旋等待一会,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。
自旋锁在JDK 1.4.2中引入,可以使用-XX:+UseSpinning参数来开启,在JDK 1.6中改为默认开启。自旋锁并不能代替阻塞,自旋的目的是为了避免频繁切换线程的开销,但如果获取锁的操作确实需要阻塞很长时间,那么自旋只会白白浪费处理器资源,因此,自旋等待的时间需要有限度,可以通过-XX:PreBlockSpin指定,默认10次。
另外,JDK 1.6中引入了自适应自旋锁,也就是根据之前在锁上自旋等待的经验来判断本次是否进行自旋等待,或本次自旋等待的次数。随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况的预测也将越来越准确。
3.4. 轻量级锁
轻量级锁是相对之前介绍的依赖系统互斥量来实现的传统锁而言的,其本意是在没有多线程竞争的前提下,减少传统重量级锁使用系统互斥量而产生的性能消耗。
要理解轻量级锁,首先得了解对象头的结构,可以分为两部分,一部分用于存储对象自身的运行时数据,称为“Mark Word”,另一部分用于存储指向方法区对象类型数据的指针。当然,如果是数组对象的话,还会有一个额外的部分用于存储数组长度。
对象头信息是与对象数据无关的额外存储成本,因此,考虑到空间使用效率,Mark Word被设计成一个非固定的数据结构以便能在极小的内存空间中存储尽量多的信息,以下是32位对象头的结构:
| 锁状态 | 25 bit | 4 bit | 1 bit | 2 bit | |
| 23 bit | 2 bit | 是否偏向锁 | 锁标志位 | ||
| 无锁 | 对象的HashCode | 分代年龄 | 0 | 01 | |
| 偏向锁 | 线程ID | Epoch | 分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中轻量级锁记录的指针 | 00 | |||
| 重量级锁 | 指向重量级锁Monitor的指针 | 10 | |||
| GC标记 | 空 | 11 | |||
- 加锁过程:
在进入同步块的时候,如果对象没有被锁定(锁状态位01),那么虚拟机首先在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前Mark Word的拷贝,称为Displaced Mark Word
然后,虚拟机使用CAS尝试将对象的Mark Word更新为指向Lock Record的指针。如果成功了,那么线程就拥有了该对象的锁,并且将Mark Word的锁标识位转为00,表示处于轻量级锁定状态。
如果失败了,虚拟机首先检查Mark Word是否指向当前线程的栈帧,如果是则说明线程已经拥有了对象的锁,那么直接进入同步块执行;否则说明锁对象已经被其他线程抢占,此时轻量级锁不再有效,将升级为重量级锁,锁标志位转为10,Mark Word指向重量级锁,线程进入阻塞,并且后面获取锁的线程都将进入阻塞。
- 解锁过程:
尝试通过CAS将对象头中的Mark Word替换为线程栈帧中的Displaced Mark Word,如果成功,则整个同步过程就完成了,否则,说明有其他线程尝试获取过该锁(Mark Word已改变,锁已膨胀),那么就要在释放锁的同时,唤醒被挂起的线程。
3.5. 偏向锁
偏向锁也是JDK 1.6引入的锁优化机制,其目的是消除数据在无竞争情况下的同步,如果说轻量级锁是在无竞争情况下使用CAS操作去消除同步使用的互斥量,那么偏向锁则连加锁和解锁时的CAS都省掉了。
当锁对象第一次被线程获取时,虚拟机将把对象头中的锁标志设为01,即偏向模式,同时使用CAS将线程ID记录在Mark Word中。如果成功,则不再需要任何同步操作。
当另一个线程尝试获取锁时,偏向模式就宣告结束,根据锁对象目前是否处于被锁定状态,决定撤销偏向后是恢复到未锁定状态还是轻量级锁定状态,然后再与之前类似进行重试。
4. Java与协程
Java语言提供了统一的线程抽象接口,来隐藏了各种操作系统线程的差异性,这曾是它区别于其它语言的一大优势。在此基础上,涌现了无数多线程的应用与框架,比如Servlet API中一个线程处理一个HTTP请求,这样语言与框架已经自动屏蔽了相当多同步和并发的复杂性,这让普通开发者能以很小的学习成本就可以完成开发任务。
但时至今日,对web应用的服务要求,无论是在请求数量还是复杂度上,都已不可同日而语,这一方面源于业务量的增长,另一方面来自于为了应对业务复杂化而不断进行的服务细分。现代B/S系统中的一次业务请求,往往需要分布在不同机器上的大量服务共同协作来实现,这种服务细分的架构在降低单个服务复杂度、增加复用性的同时,也增加了服务的数量,缩短了留给每个服务的响应时间,即要求每个服务都必须在极短的时间内响应,这样组合多个服务的总耗时才不会太长。
这就与Java虚拟机目前基于内核线程的实现产生了矛盾,这种映射到操作系统上的线程在切换和调度操作上存在天然的缺陷,其代价高昂,并且系统本身能容纳的线程数量也很有限。传统的Web服务器的线程池可以在几十到几百之间,但当存在百万记的请求需要处理时,即使系统能处理得过来,其中的切换消耗也是相当可观的。
内核线程的调度成本主要来自于用户态与内核态之间的切换,而这两种状态切换的开销主要来自于响应中断、保护和恢复执行线程的成本,这也就是上面锁优化的目的,尽量避免导致线程挂起和恢复的操作。
处理器执行线程A的操作时,并不是只有代码程序就能跑起来,程序是数据和代码的结合,代码执行时还必须有上下文数据的支撑。而这些数据则存储在内存、缓存和寄存器中,并且这些计算机资源是所有线程共享的,
假设发生这样一次线程切换线程A -> 系统中断 -> 线程B,当从线程A切换到线程B执行之前,操作系统首先要把线程A的上下文数据保存好,然后再把寄存器、内存分页等恢复到线程B挂起时的状态,这样线程B唤醒后才能正常执行。所以,这种保护和恢复线程的工作,免不了涉及一系列数据在各种缓存器、缓存中的来回拷贝,显然不可能是一种轻量级的操作。
所以,如果改为采用用户线程,将这种保护、恢复现场以及调度的工作从操作系统交到开发人员手上,那么就可以想一些办法来缩减开销。
由于多数的用户线程被设计成协同式调度,因此它有了一个别名:协程。其大致原理是通过在内存中划出一片额外空间来模拟调用栈,只要其他线程中方法压栈、退栈时遵守规则,不破坏这片空间即可。所以有时也称为:有栈协程,但不等于协程就一定是以协同调度的方式工作,也存在非协同式、可自定义调度的协程实现。
协程的主要优势在于轻量,比如在Linux 64位上的HotSpot中,线程栈的容量默认位1MB(也可以通过-Xss或-XX:ThreadStackSize设置),此外内核数据结构还会消耗额外16KB内存。与之相对的,一个协程的栈通常只在几百字节到几KB之间,所以在Java虚拟机的线程池容量达到两百已经不算小了,而如果使用协程,则可以以十万计。
OpenJDK在2018年创建了Loom项目,其背后的意图是重新提供对用户线程的支持,以解决上面提到的目前Java面临的困境。当然,这并不是为了取代之前基于操作系统线程的实现,而是会有两个并发编程模型在Java虚拟机中并存。新模型会有意地保持与目前线程模型相似的API设计,它们甚至可以拥有一个共同的基类,这样现有的代码就不需要为了新模型而进行过多的改动。
参考: