Spring在前面的基础上,提供了JDBC模块,其中包括了对jdbc和datasource等的封装,这里先简单梳理下其中的JdbcTemplate,它是一个对JDBC使用的封装,提供了一套的模板,能让我们写持久层代码时减少多余的代码,简化JDBC代码,使代码看起来更简洁。
Jdbc JDBC(Java Data Base Connectivitys)是java为关系型数据库驱动执行SQL提供的一套接口,其实就是制定了一个标准,具体可以分为下面几个步骤:
1.加载数据库驱动,并注册到DriverManager中(对于注册动作要求数据库驱动自己完成)
其中,Jdbc要求数据库厂商提供的Driver在加载自己的时候将自己注册到DriverManager中,这样当用户加载数据库驱动时,比如Class.forName(xxx.Driver),其实也就完成了注册,不过从 Jdbc4.0 开始,可以省掉手动加载数据库驱动这个步骤了,当然如果手动加载也仍然有效
Applications no longer need to explicitly load JDBC drivers using Class.forName(). Existing programs which currently load JDBCClass.forName() will continue to work withoutmodification.
原因是DriverManager会在其静态域中尝试从类路径下面检测和加载各种Driver
:java.sql.DriverManager 1 2 3 4 static { loadInitialDrivers(); println("JDBC DriverManager initialized" ); }
2.创建Connection
Connection是对连接的封装,由于连接都是可复用的,而且创建有一定的代价,所以一般会将Connection的创建交给连接池DataSource代理,连接池再将实际的创建委托给DriverManager,并对创建过的Connection进行缓存管理
:javax.sql.DataSource 1 2 3 4 5 6 public interface DataSource extends CommonDataSource , Wrapper { Connection getConnection () throws SQLException; Connection getConnection (String username, String password) throws SQLException; }
3.创建Statement
Statement则是对执行SQL的封装,相当于sql执行器,当然它也是可以缓存复用的,如果下次sql相同,那么直接就可以使用之前创建的
4.执行sql,获取结果
如果是查询,会返回一个ResultSet,其中封装了返回的数据,可以遍历获取
对于上面的过程,可以简单画一个示意图来表示:
示例 按照上面的步骤,实现一个jdbc的简单示例
:TestJdbc.java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class TestJdbc { public static void main (String[] args) throws ClassNotFoundException, SQLException { Class.forName("oracle.jdbc.driver.OracleDriver" ); try (Connection connection = DriverManager.getConnection("jdbc:oracle:thin:@192.168.141.21:1521:orcl" , "scott" , "admin" ); Statement statement = connection.createStatement();){ String sql = "SELECT id, name FROM user" ; try (ResultSet rs = statement.executeQuery(sql);){ while (rs.next()){ System.out.println(rs.getInt("id" )); System.out.println(rs.getString("name" )); } } } } }
JdbcTemplate 下面使用spring提供的JdbcTemplate,看下其是如何让jdbc的使用变得更方便的
示例 :pom.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <dependency > <groupId > org.springframework</groupId > <artifactId > spring-core</artifactId > <version > 5.1.3.RELEASE</version > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-beans</artifactId > <version > 5.1.3.RELEASE</version > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-context</artifactId > <version > 5.1.3.RELEASE</version > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-jdbc</artifactId > <version > 5.1.3.RELEASE</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 8.0.13</version > </dependency >
:User.java 1 2 3 4 5 6 7 8 9 10 11 12 13 public class User { private long id; private String name; public User (long id, String name) { this .id = id; this .name = name; } }
:UserRowMapper.java 1 2 3 4 5 6 7 public class UserRowMapper implements RowMapper <User> { @Override public User mapRow (ResultSet resultSet, int index) throws SQLException { return new User (resultSet.getLong("id" ), resultSet.getString("name" )); } }
:UserService.java 1 2 3 4 5 6 public interface UserService { void save (User user) ; List<User> query () ; }
:UserServiceImpl.java mark:11,16 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class UserServiceImpl implements UserService { private JdbcTemplate jdbcTemplate; public void setDataSource (DataSource dataSource) { jdbcTemplate = new JdbcTemplate (dataSource); } @Override public void save (User user) { jdbcTemplate.update("insert into user(id, name)values(?, ?)" , new Object []{user.getId(), user.getName()}); } @Override public List<User> query () { return jdbcTemplate.query("select id, name from user" , new UserRowMapper ()); } }
:bean.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?xml version="1.0" encoding="UTF-8" ?> <beans xmlns ="http://www.springframework.org/schema/beans" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" > <bean id ="dataSource" class ="org.springframework.jdbc.datasource.DriverManagerDataSource" > <property name ="driverClassName" value ="com.mysql.cj.jdbc.Driver" /> <property name ="url" value ="jdbc:mysql://192.168.141.13:3306/demo" /> <property name ="username" value ="shanhm" /> <property name ="password" value ="shanhm" /> </bean > <bean id ="userService" class ="test.springjdbc.UserServiceImpl" > <property name ="dataSource" ref ="dataSource" /> </bean > </beans >
:App.java 1 2 3 4 5 6 7 8 9 10 11 12 public class App { public static void main (String[] args) { ApplicationContext context = new ClassPathXmlApplicationContext ("bean.xml" ); UserService userService = context.getBean(UserService.class); User user = new User (1 , "shanhm1991" ); userService.save(user); List<User> userList = userService.query(); } }
实现 JdbcTemplate实现中以execute为核心,至于其它的操作在其基础上传入不同的回调接口PreparedStatementCallback
其思路也比较清晰:
1.获取Connection
这里连接的获取和释放主要考虑了事务问题,具体后面介绍spring事务时再详细梳理
2.创建PreparedStatement或者Statement,并进行设置
区别在于PreparedStatement对sql进行了预编译,以便可以复用提高效率,设置主要是针对fetchSize属性,它表示调用ResultSet.next时,会一次性从服务器上取多少行数据,这样减少网络交互,提高效率,不过有些JDBC驱动会忽略这个属性,而且设置过大会造成内存消耗
3.在回调中进行参数设置和执行,不同的方法提供不同的回调实现
4.结果处理,释放连接
:org.springframework.jdbc.core.JdbcTemplate mark:10,13-16,27,35 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public <T> T execute (PreparedStatementCreator psc, PreparedStatementCallback<T> action) throws DataAccessException { Assert.notNull(psc, "PreparedStatementCreator must not be null" ); Assert.notNull(action, "Callback object must not be null" ); if (logger.isDebugEnabled()) { String sql = getSql(psc); logger.debug("Executing prepared SQL statement" + (sql != null ? " [" + sql + "]" : "" )); } Connection con = DataSourceUtils.getConnection(obtainDataSource()); PreparedStatement ps = null ; try { ps = psc.createPreparedStatement(con); applyStatementSettings(ps); T result = action.doInPreparedStatement(ps); handleWarnings(ps); return result; }catch (SQLException ex) { if (psc instanceof ParameterDisposer) { ((ParameterDisposer) psc).cleanupParameters(); } String sql = getSql(psc); JdbcUtils.closeStatement(ps); ps = null ; DataSourceUtils.releaseConnection(con, getDataSource()); con = null ; throw translateException("PreparedStatementCallback" , sql, ex); }finally { if (psc instanceof ParameterDisposer) { ((ParameterDisposer) psc).cleanupParameters(); } JdbcUtils.closeStatement(ps); DataSourceUtils.releaseConnection(con, getDataSource()); } }
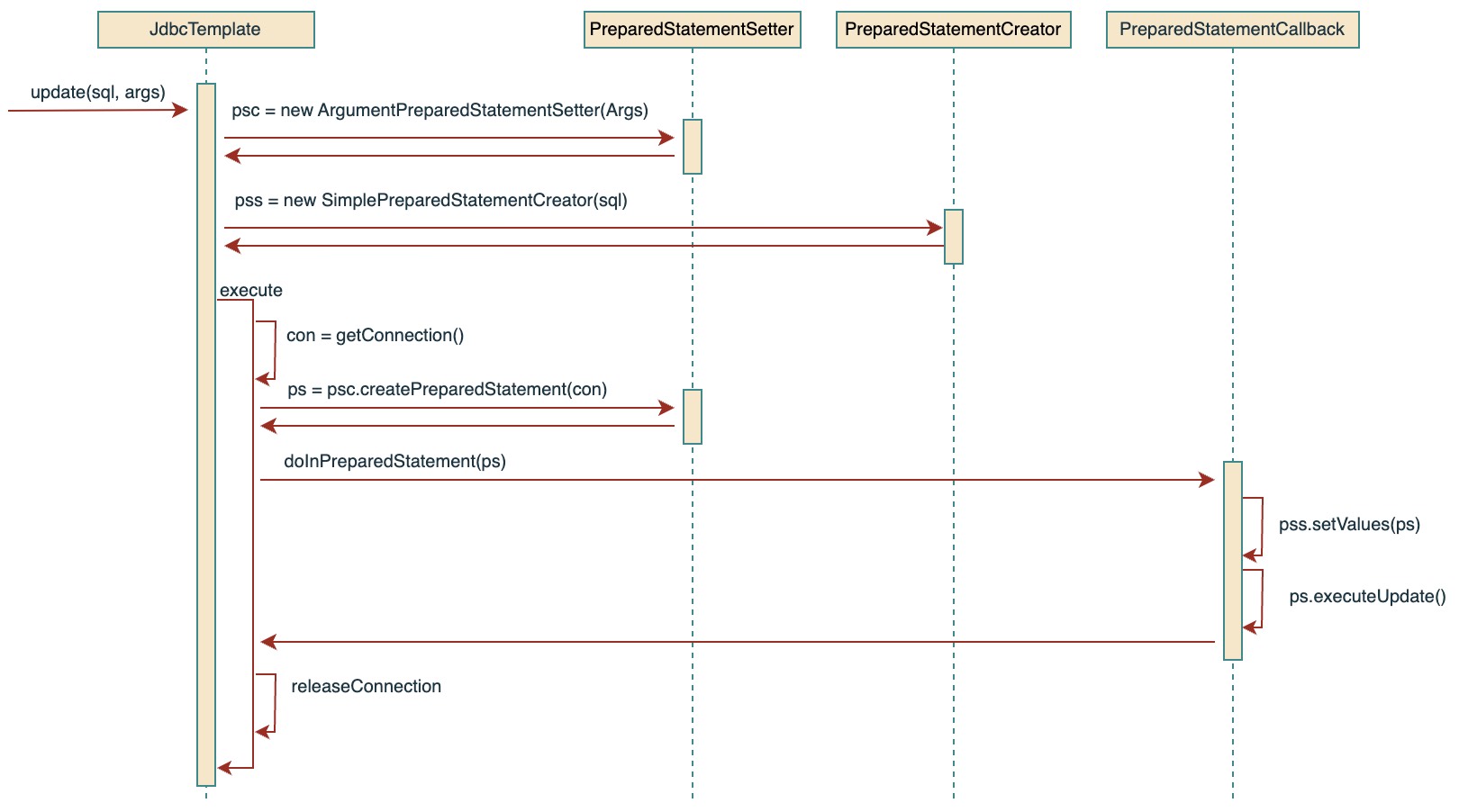
update 上面的execute接收一个PreparedStatementCreator和PreparedStatementCallback,就是将Statement的创建和参数填充以及执行都交给了具体的方法负责
下面看下update是如何实现的:
首先它先根据传入的sql和参数分别构造了PreparedStatementCreator和PreparedStatementSetter,也就是提前定义了PreparedStatement的如何创建以及如何填充参数,然后在调用execute时再构造PreparedStatementCallback,也就是定义了PreparedStatement的参数填充时机以及如何执行,至于具体参数如何填充则使用前面已经定义的PreparedStatementSetter
也就是将PreparedStatement的创建交给了PreparedStatementCreator定义,将PreparedStatement的参数填充交给了PreparedStatementSetter定义,然后再将PreparedStatementSetter以及PreparedStatement的调用交给了PreparedStatementCallback定义,这样,对于PreparedStatement的创建、参数填充、以及执行实现了高度解耦和定制化
:org.springframework.jdbc.core.PreparedStatementCallback 1 2 3 public interface PreparedStatementCallback <T> { T doInPreparedStatement (PreparedStatement ps) throws SQLException, DataAccessException; }
:org.springframework.jdbc.core.JdbcTemplate mark:7,9 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 protected int update (final PreparedStatementCreator psc, @Nullable final PreparedStatementSetter pss) throws DataAccessException { logger.debug("Executing prepared SQL update" ); return updateCount(execute(psc, ps -> { try { if (pss != null ) { pss.setValues(ps); } int rows = ps.executeUpdate(); if (logger.isTraceEnabled()) { logger.trace("SQL update affected " + rows + " rows" ); } return rows; }finally { if (pss instanceof ParameterDisposer) { ((ParameterDisposer) pss).cleanupParameters(); } } })); }
具体的过程可以画一个简单的时序图来描述:
query 再看一下示例中query的实现,这里没有参数,所以也就不需要传入PreparedStatementSetter,不过传入的RowMapper,会将其构造一个ResultSetExtractor,然后在回调中执行Statement拿到结果后,会将结果交给ResultSetExtractor执行,就是说用户可以将如何封装结果定义在RowMapper,然后查询的时候由ResultSetExtractor负责调用,这里的回调以及execute与上面update不同,但是思路都是类似的,不再赘述。
:org.springframework.jdbc.core.JdbcTemplate mark:14,15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public <T> T query (final String sql, final ResultSetExtractor<T> rse) throws DataAccessException { Assert.notNull(sql, "SQL must not be null" ); Assert.notNull(rse, "ResultSetExtractor must not be null" ); if (logger.isDebugEnabled()) { logger.debug("Executing SQL query [" + sql + "]" ); } class QueryStatementCallback implements StatementCallback <T>, SqlProvider { @Override @Nullable public T doInStatement (Statement stmt) throws SQLException { ResultSet rs = null ; try { rs = stmt.executeQuery(sql); return rse.extractData(rs); }finally { JdbcUtils.closeResultSet(rs); } } @Override public String getSql () { return sql; } } return execute(new QueryStatementCallback ()); }
queryForObject spring在query的基础上还提供了queryForObject,其实它就是根据给定的类型class帮用户构造了一个RowMapper
:org.springframework.jdbc.core.JdbcTemplate 1 2 3 4 5 6 7 public <T> T queryForObject (String sql, Class<T> requiredType) throws DataAccessException { return queryForObject(sql, getSingleColumnRowMapper(requiredType)); } protected <T> RowMapper<T> getSingleColumnRowMapper (Class<T> requiredType) { return new SingleColumnRowMapper <>(requiredType); }
不过这里创建的RowMapper只能对单列数据进行处理,当然对于自定义的类型转换,spring也提供了对应的BeanPropertyRowMapper,如果还是不够用,比如转换转换过程涉及到一些逻辑处理那就只能自己定义了
:org.springframework.jdbc.core.SingleColumnRowMapper mark:14 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public T mapRow (ResultSet rs, int rowNum) throws SQLException { ResultSetMetaData rsmd = rs.getMetaData(); int nrOfColumns = rsmd.getColumnCount(); if (nrOfColumns != 1 ) { throw new IncorrectResultSetColumnCountException (1 , nrOfColumns); } Object result = getColumnValue(rs, 1 , this .requiredType); if (result != null && this .requiredType != null && !this .requiredType.isInstance(result)) { try { return (T) convertValueToRequiredType(result, this .requiredType); }catch (IllegalArgumentException ex) { throw new TypeMismatchDataAccessException ( "Type mismatch affecting row number " + rowNum + " and column type '" + rsmd.getColumnTypeName(1 ) + "': " + ex.getMessage()); } } return (T) result; } protected Object convertValueToRequiredType (Object value, Class<?> requiredType) { if (String.class == requiredType) { return value.toString(); }else if (Number.class.isAssignableFrom(requiredType)) { if (value instanceof Number) { return NumberUtils.convertNumberToTargetClass(((Number) value), (Class<Number>) requiredType); }else { return NumberUtils.parseNumber(value.toString(),(Class<Number>) requiredType); } }else if (this .conversionService != null && this .conversionService.canConvert(value.getClass(), requiredType)) { return this .conversionService.convert(value, requiredType); }else { throw new IllegalArgumentException ( "Value [" + value + "] is of type [" + value.getClass().getName() + "] and cannot be converted to required type [" + requiredType.getName() + "]" ); } }
参考:
《spring源码深度解析》 郝佳