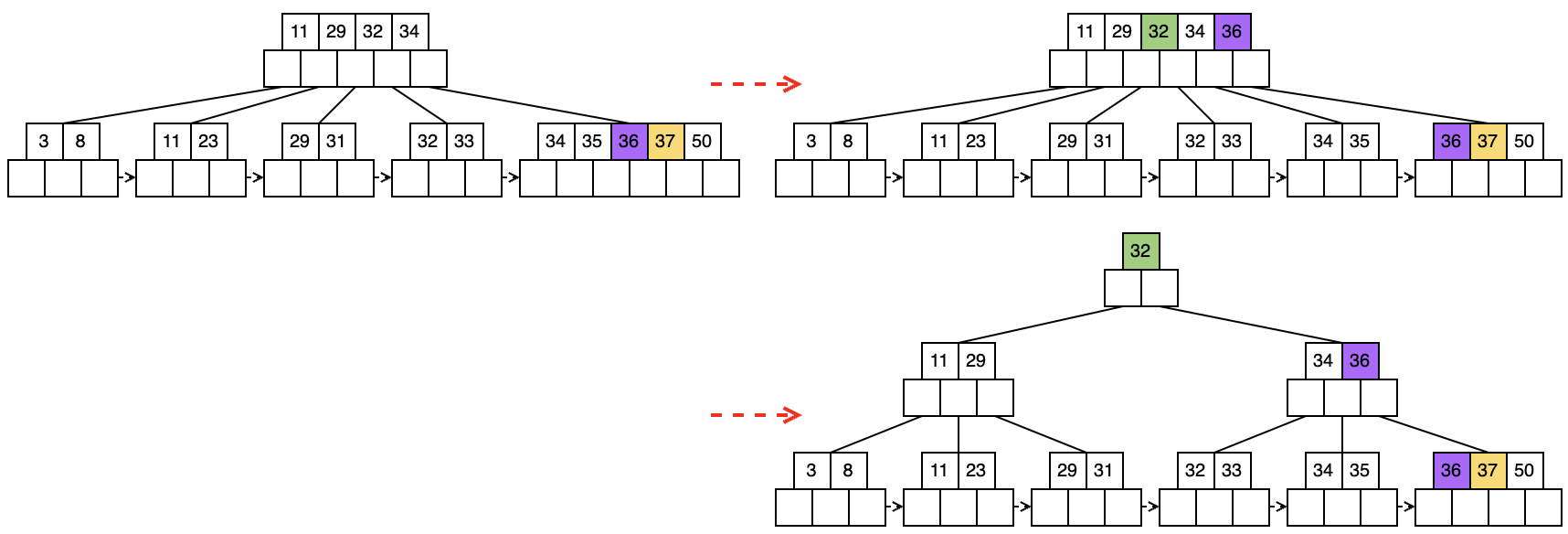
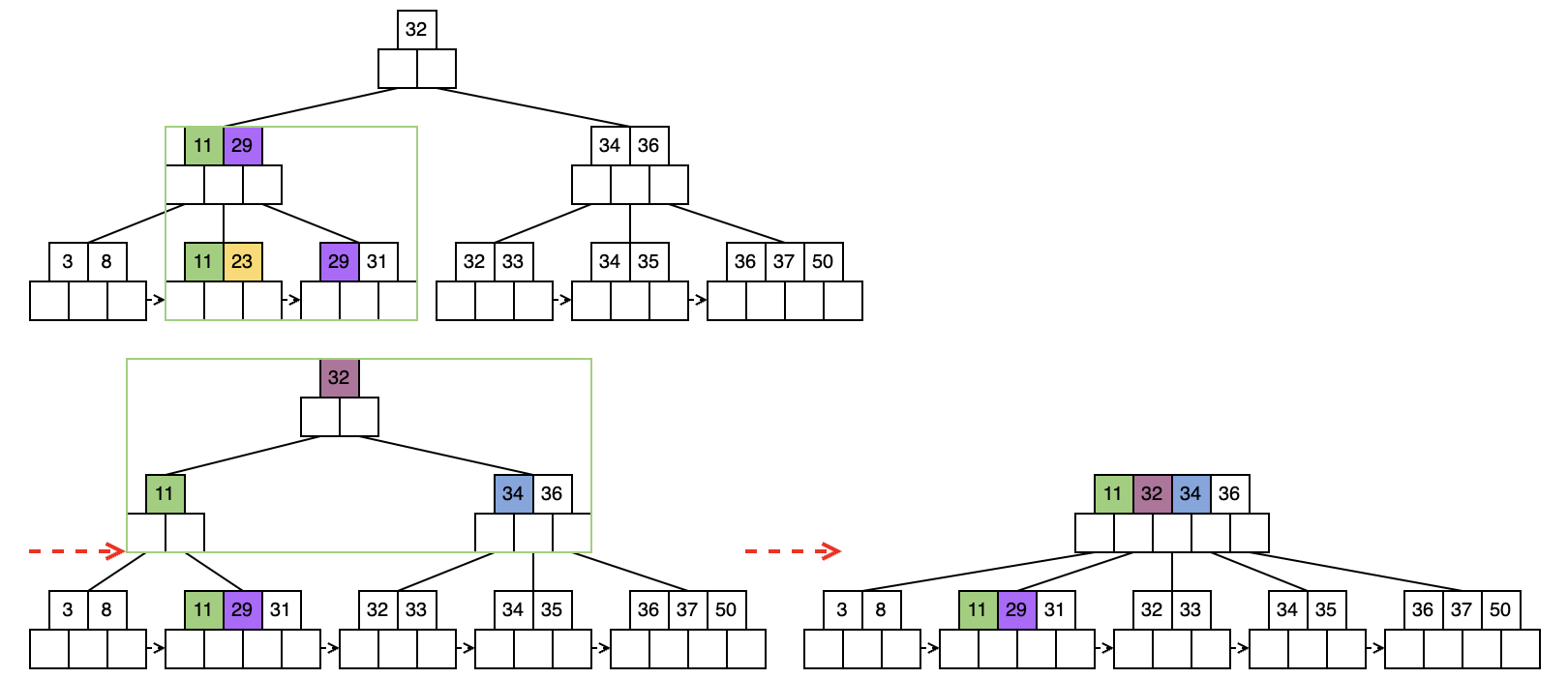
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
| public class ExtendBTree<E extends Comparable<? super E>> extends BTree<E> {
private ENode<E> root;
public ExtendBTree(int m) {
super(m);
this.root = new ENode<>(m, null, null);
}
private static class ENode<E> extends BTree.Node<E> {
ENode<E> next;
ENode(int m, Entry<E> leftEntry, Entry<E> rightEntry) {
super(m, leftEntry, rightEntry);
}
}
@Override
protected Node<E> getRoot() {
return root;
}
@Override
public void clear() {
root = new ENode<>(m, null, null);
size = 0;
}
@Override
public void add(E e){
add(e, root, height);
}
@Override
protected void fixAdd(Node<E> node, int ht) {
if(ht == 0){
fixLeafAdd((ENode<E>)node, ht);
}else{
super.fixAdd(node, ht);
}
}
private void fixLeafAdd(ENode<E> leaf, int ht){
if(leaf.entrys[m - 1] == null){
return;
}
Entry<E>[] entrys = leaf.entrys;
Entry<E> middle = entrys[middleIndex + 1];
Entry<E> created = new Entry<>(middle.element, 0, null, null, null);
ENode<E> right = new ENode<>(m, created, null);
leaf.next = right;
created.leftNode = leaf;
created.rightNode = right;
initEntrys(leaf, m);
System.arraycopy(entrys, 0, leaf.entrys, 0, middleIndex + 1);
System.arraycopy(entrys, middleIndex + 1, right.entrys, 0, middleIndex + 2);
fixEntryNode(right.entrys, right);
fixIndex(0, right);
if(leaf.leftEntry != null){
Entry<E> preEntry = leaf.leftEntry;
Node<E> parent = preEntry.node;
int index = preEntry.index;
Entry<E> afterEntry = parent.entrys[index + 1];
if(afterEntry != null){
afterEntry.leftNode = right;
}
right.rightEntry = afterEntry;
leaf.rightEntry = created;
System.arraycopy(parent.entrys, index + 1, parent.entrys, index + 2, m - index - 2);
parent.entrys[index + 1] = created;
created.node = parent;
fixIndex(index, parent);
fixAdd(parent, ht + 1);
}else if(leaf.rightEntry != null){
Entry<E> afterEntry = leaf.rightEntry;
Node<E> parent = afterEntry.node;
afterEntry.leftNode = right;
right.rightEntry = afterEntry;
leaf.rightEntry = created;
int index = afterEntry.index;
System.arraycopy(parent.entrys, index, parent.entrys, index + 1, m - index - 1);
parent.entrys[index] = created;
created.node = parent;
fixIndex(index, parent);
fixAdd(parent, ht + 1);
}else{
height++;
root = new ENode<>(m, null, null);
root.entrys[0] = created;
created.node = root;
}
}
@Override
public void remove(E e) {
}
@Override
public String toString() {
Entry<E> entry = findMin(root, height);
ENode<E> node = (ENode<E>)entry.node;
List<E> list = new LinkedList<>();
build(list, node);
while((node = node.next) != null){
build(list, node);
}
return list.toString();
}
private void build(List<E> list, ENode<E> node){
for(Entry<E> entry : node.entrys){
if(entry == null){
return;
}
list.add(entry.element);
}
}
}
|