节点间数据同步设计
words: 2.4k views: time: 8min背景
对于数据的同步一般会想办法在数据库层解决,比较直接而且也有成熟的解决方案。但有时我们并不希望对整个库进行同步,只想对某些指定的业务模型数据进行同步。而且在有的场景下,可能希望在同步过程中插入一些操作,比如在合并时对变更的内容进行审查和修改,并在合并完成之前,仍然使用之前的数据;
所以希望设计一种通用的办法,让存在于各个系统节点中的数据能够各自进行变化,并保持数据一致,即便出现网络断开的情况。
思路
选择一个节点作为中心节点,然后统一以中心节点的数据版本为准,所有节点都将自己的数据变化上报给中心节点,由中心节点进行合并,然后再分发给所有节点。具体需要添加一些辅助字段来跟踪数据的版本和状态,并约定它们的变化规则。
需要考虑的问题:
1.数据应该是以实际的业务实体为单位来进行同步,而不是针对某个库或某张表。比如一个人除了基本信息,还有部门信息,角色或者权限等;
2.数据变化在合并生效之前不应该影响当前的数据使用,并且允许撤销变化;
3.添加辅助字段不能直接修改原数据表结构,这样会影响已经存在的业务功能设计,需要另外记一份副本数据,将辅助字段加在副本上;
4.需要考虑中心节点断连的场景,以及当断连的中心节点恢复之后,保证所有的变更记录不会丢失;
具体的字段设计如下:
- loacal;跟踪本地节点数据版本,每次变化都会更新local值,并取当前local的最大值加1
- remote:跟踪同步的中心节点数据版本,每次只会从中心节点拉取local大于本地remote最大值的变更记录,并在拉取后使用中心节点的local值更新本地的local和remote(对于新增类型的变更记录,remote直接置0)
- dataNode:记录发起数据新增的系统节点,更新操作不会改变dataNode
- dataSyn:标记数据变更是否已经推送到中心节点,如果本身是中心节点,则直接置1
- dataMerge:标记数据变更在中心节点中是否已经合并
- dataOperation:记录数据变更的操作类型 1:新增;2:更新;3:删除
借助这些辅助字段,可以演示一下数据A(这里A表示一份业务模型数据,红色表示相对之前发生了变化)变更为A1的主要过程:
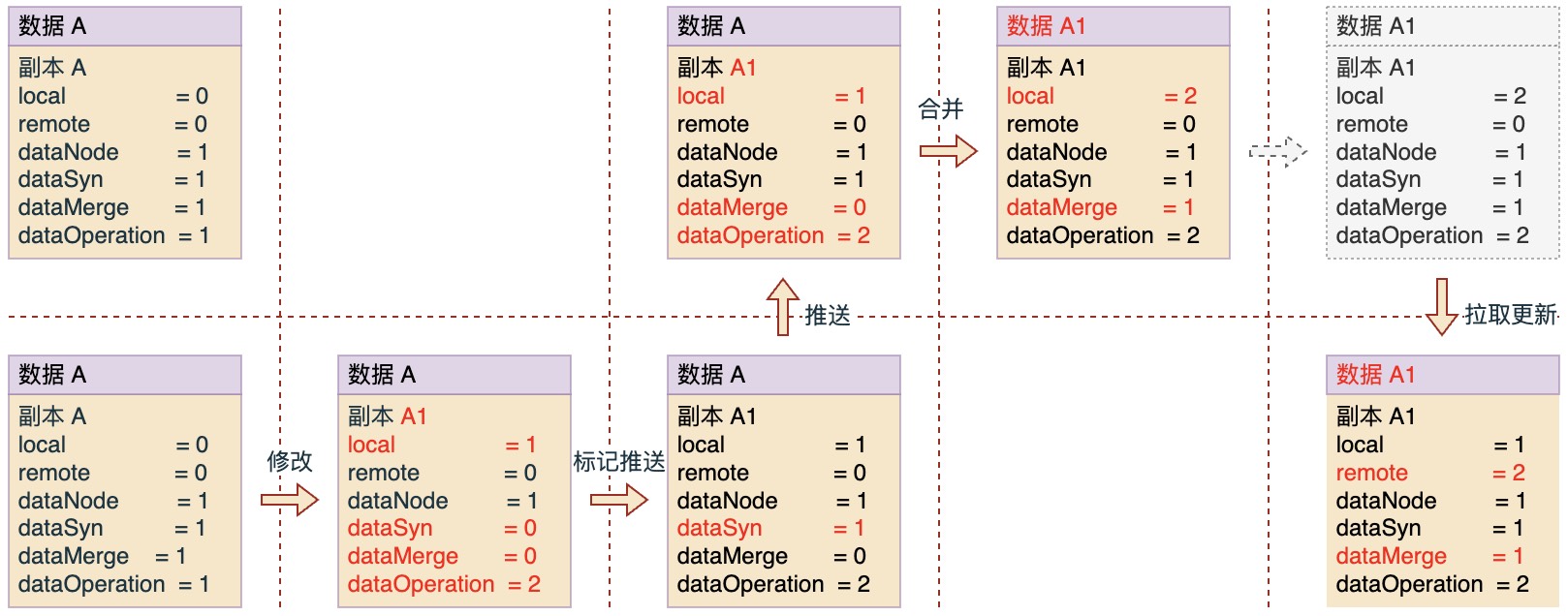
图中上下分为两个不同系统节点中的数据,以上面作为中心节点的数据。初始数据一致,然后分为4个步骤:修改 -> 推送 -> 合并 -> 拉取。
在每个步骤中,辅助字段会根据约定的规则进行变化,不过所有这些过程都只在副本数据上体现,最终才将变化的结果同步到原数据上。另外对于副本,我们还会添加一个id标识字段,这样通过id和dataNode字段信息,我们就能确定中心节点收到的推送数据是对应哪个节点中的哪条副本记录。
示例推演
下面来做一个示例推演:假设有1、2、3三个节点,以节点1作为中心节点,并且它们的初始数据保持一致。

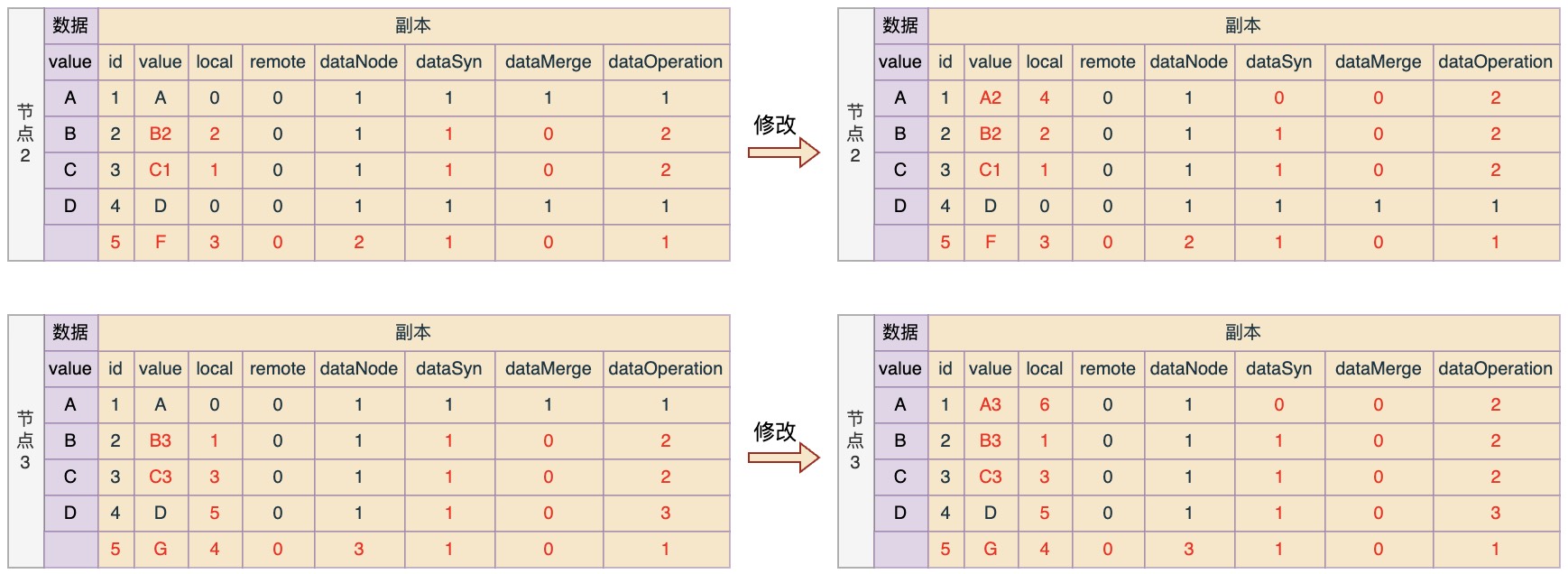
修改
修改规则:
- 对于任何修改,都会更新local值,并且是取当前最大local值加1;
- 修改之后,dataSyn更新为0,如果是中心节点则保持1不变;
- 修改之后,dataMerge更新为0;
- 如果是新增操作,则dataNode记为当前节点标识,否则保持不变;
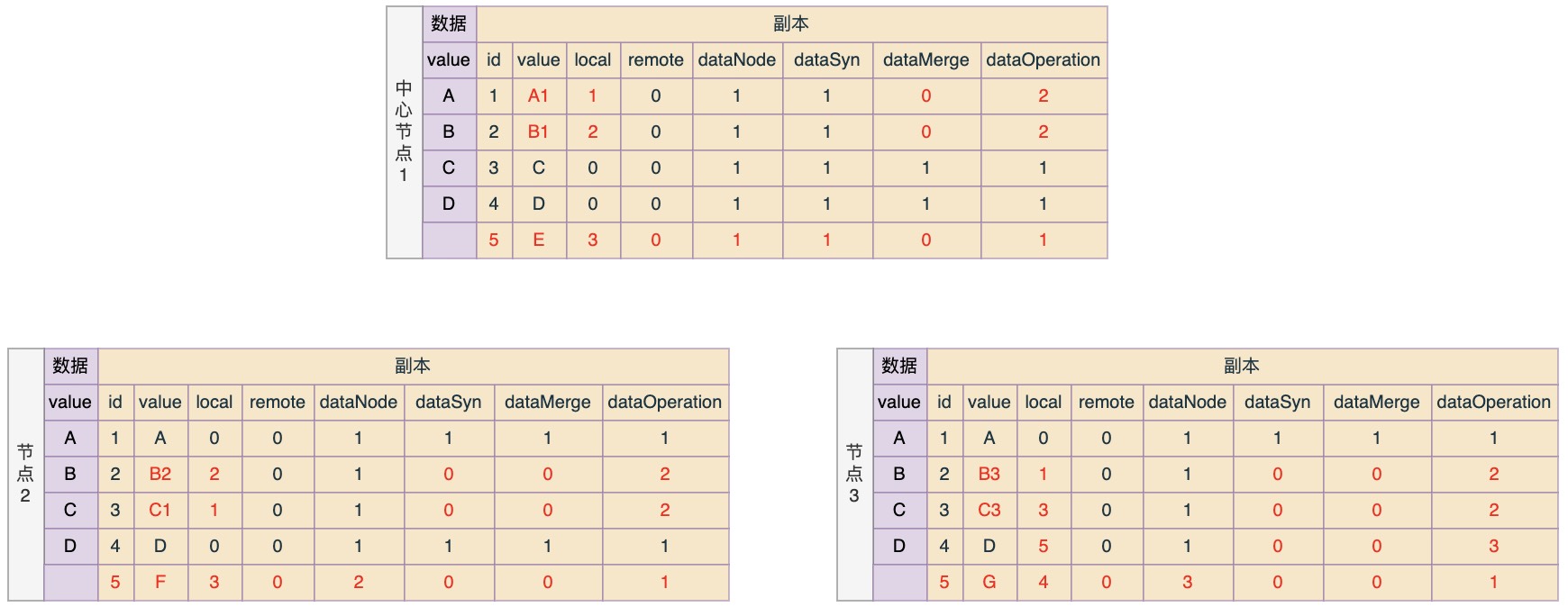
现在假设断开连接,然后节点各自进行数据变化,并且数据变化情况如下:
节点1:数据A变更为A1;数据B变更为B1;新增数据E
节点2:数据C变更为C1;数据B变更为B2;新增数据F
节点3:数据B变更为B3;数据C变更为C2;数据C2变更为C3;新增数据G;删除数据D
那么按照规则,修改之后各节点中的数据状态应该如下(红色是表示一些发生了变化的信息,以下类似):
推送
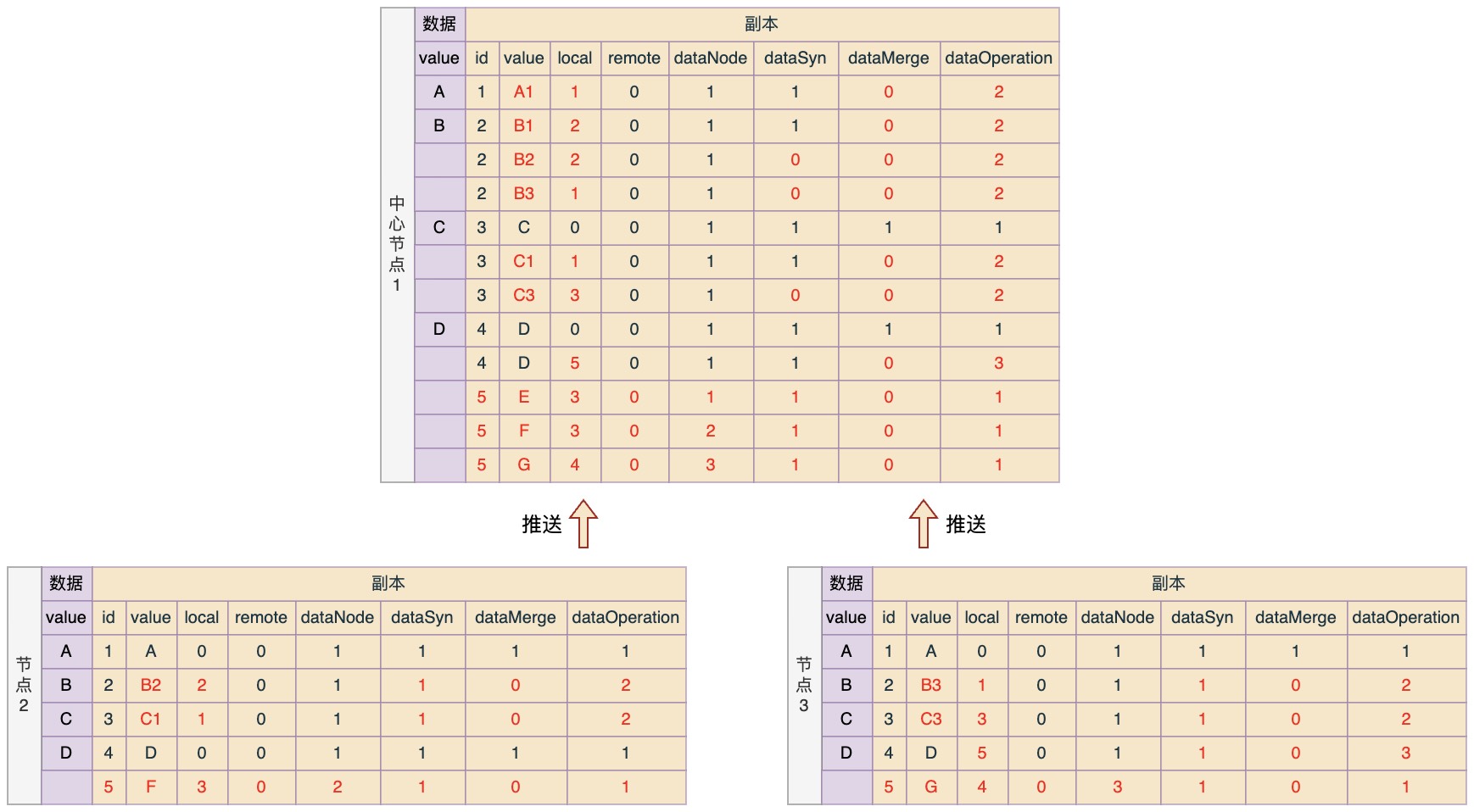
推送规则:非中心节点取所有dataSyn=0的副本记录进行推送,推送成功之后将dataSyn更新为1
那么按照规则,推送之后各节点中数据状态应该如下所示:
合并
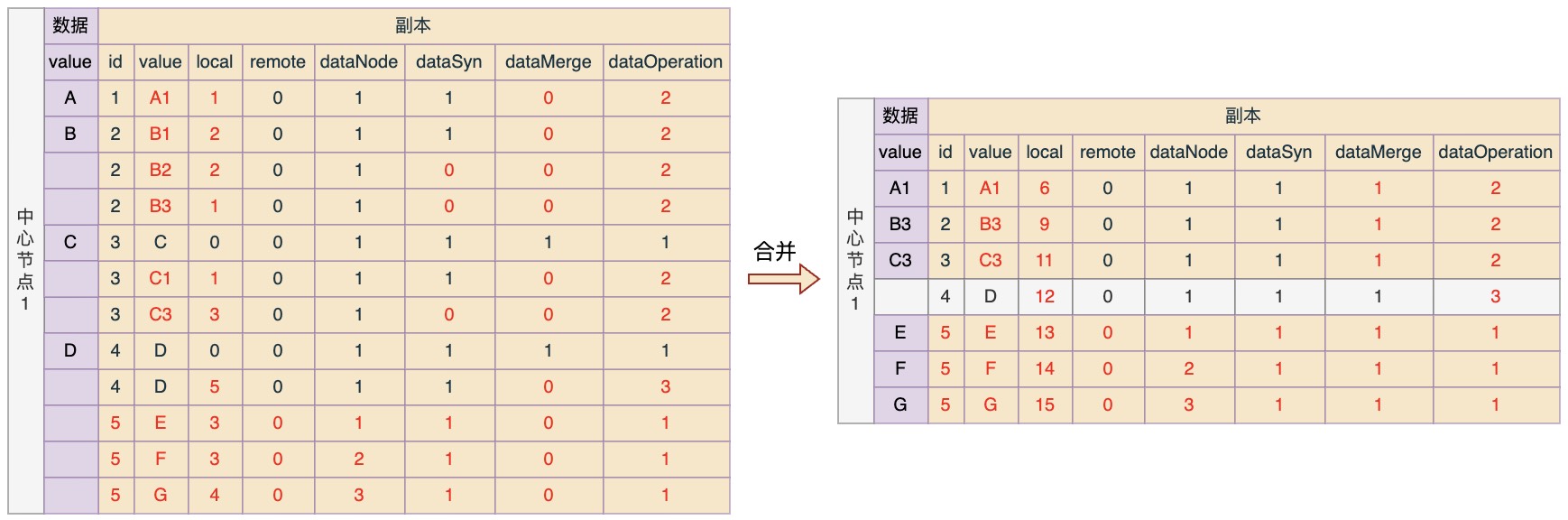
合并规则:
- 中心节点对于变更副本逐条进行合并,每个合并操作都视为一次更新操作,因此都会更新local值;
- 如果dataOperation = 1,表示新增,那么直接插入新数据;
- 如果dataOperation = 2,表示更新,那么根据数据本身标识对原数据进行更新;
- 如果dataOperation = 3,表示删除,那么根据数据本身标识删除原数据,但是副本记录不删,可能还有其它节点没有同步。如果中心节点想删除这个副本记录,可以发起一个请求去询问各个节点是否已经拉取并删除了这个副本对应的原数据,当所有节点都回复是的时候就可以删了;
那么按照规则,节点1在合并之后的数据应该如下所示:
拉取
拉取规则:
- 需要保证拉取的是上次拉取之后发生的变化,并且是已经合并完的变化。所以在拉取请求中需要带上本地remote最大值,然后中心节点在返回副本数据时必须满足条件:local > remote(请求) && dataApprove = 1;
- 在拉取变更之后,更新本地数据时是采用覆盖的策略,也就是存在则更新,不存在则新增。但是不能丢失本地还没有推送的变更副本,因此对于dataSyn = 0的副本,在更新时只修改它的remote值,以及对应的原数据;
这里假设在拉取之前,并在上次推送完成之后,节点2和3中的数据又发生了变化:节点2中的数据A变化为A2,节点3中的数据A变化为A3。
那么按照规则,在拉取更新之后,各节点数据应该如下所示
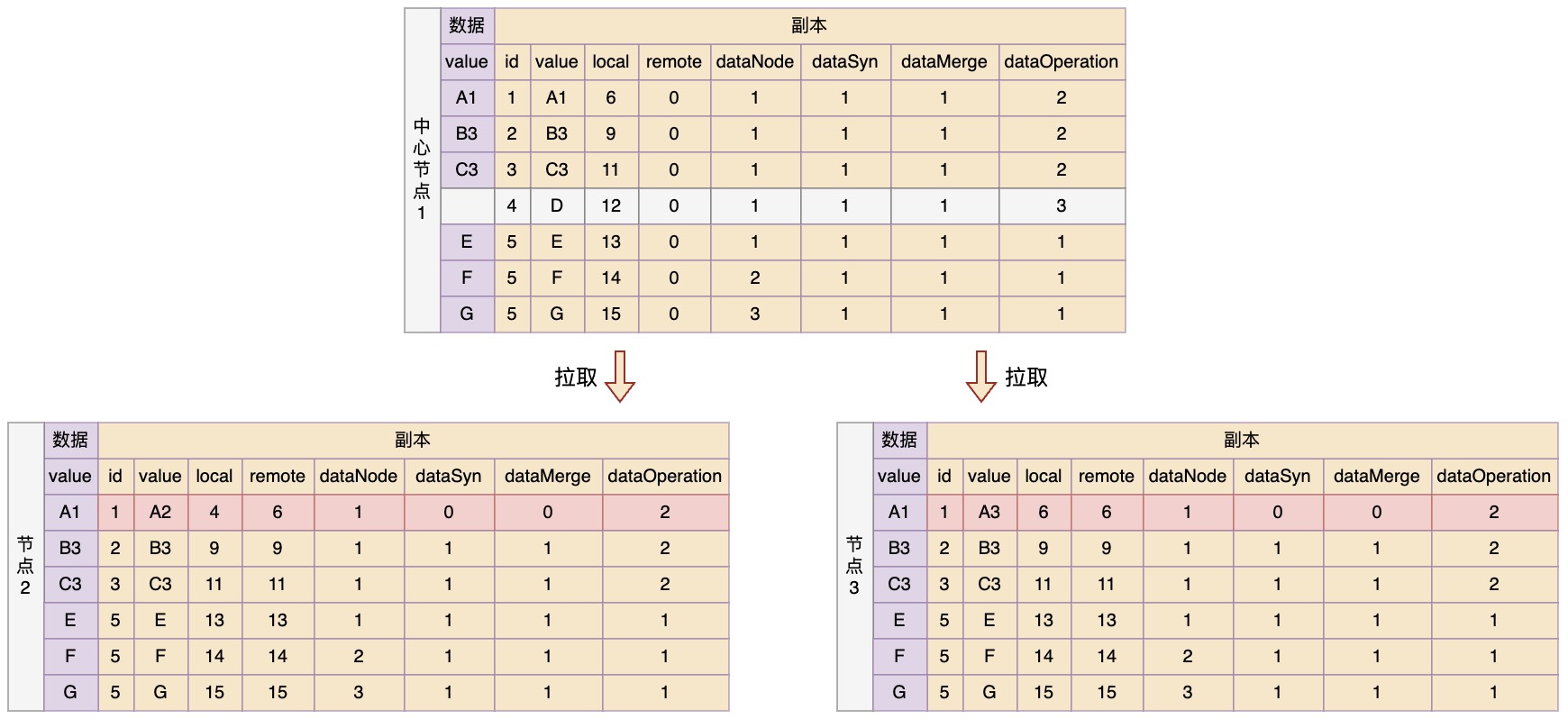
可以看到,相对初始状态,三个节点中的数据在变化之后又重新达到了一致的状态,只是有两个变更副本还没有合并生效,但是也会在下一次推送合并拉取之后,再次达到一致。
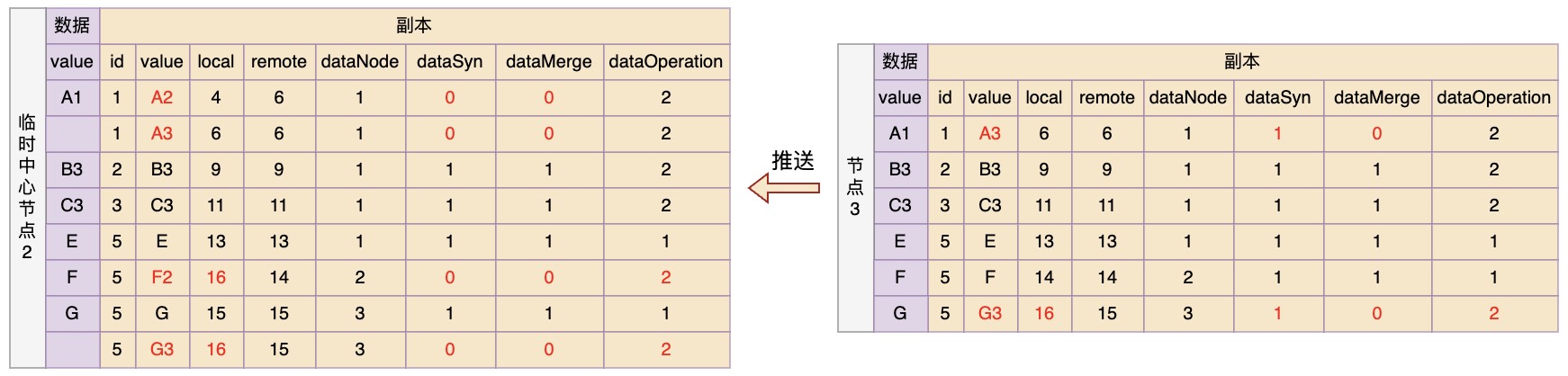
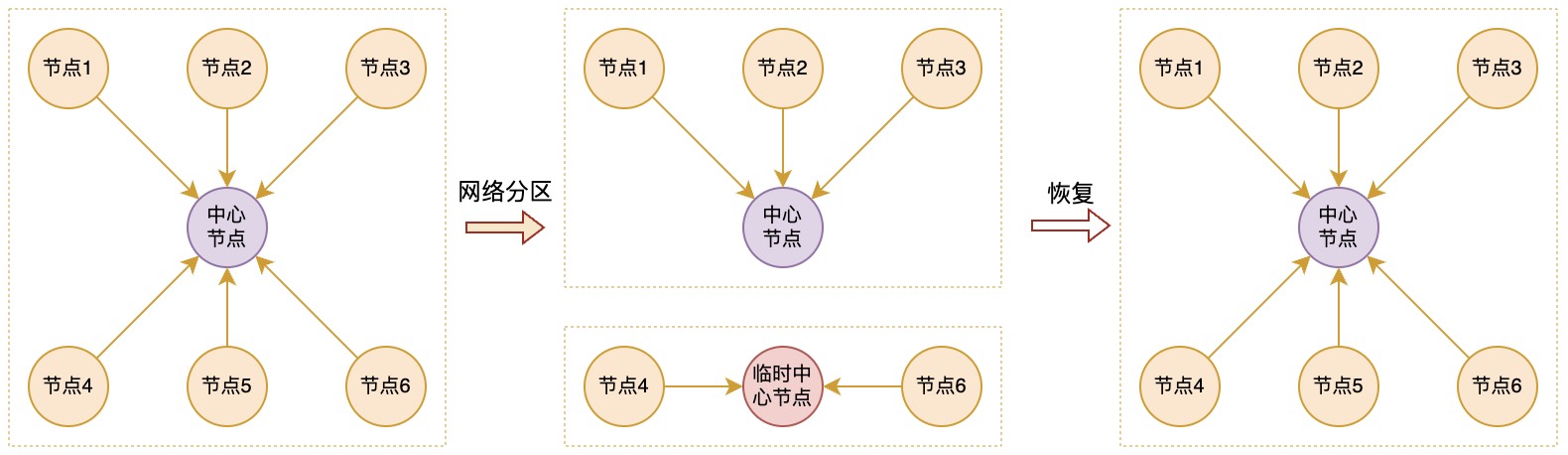
中心节点断连
如果出现中心节点断连,可以在当前可以连接到的节点中选举一个remote值最大的节点作为临时中心节点,然后让其它的节点将变更副本都向临时中心节点进行推送。然后之前的规则保持不变,只是从此刻开始,临时节点中的dataSyn全部记为0。这样如果以后中心节点恢复,还能将中心节点的身份还给它,并将从断开那一刻之后发生的数据变更推送给它;
现在假设节点1出现断连,然后选举节点2作为临时中心节点,并且在断连之后,节点2和3中的数据又发生了变化,变化情况如下:
节点2:数据F变更为F2
节点3:数据G变更为G3

然后节点3向临时中心节点2推送变更记录,根据规则,推送之后数据状态应该如下
临时中心节点2在收到推送的变更后进行合并,复用之前的规则,只是dataSyn全部记为0
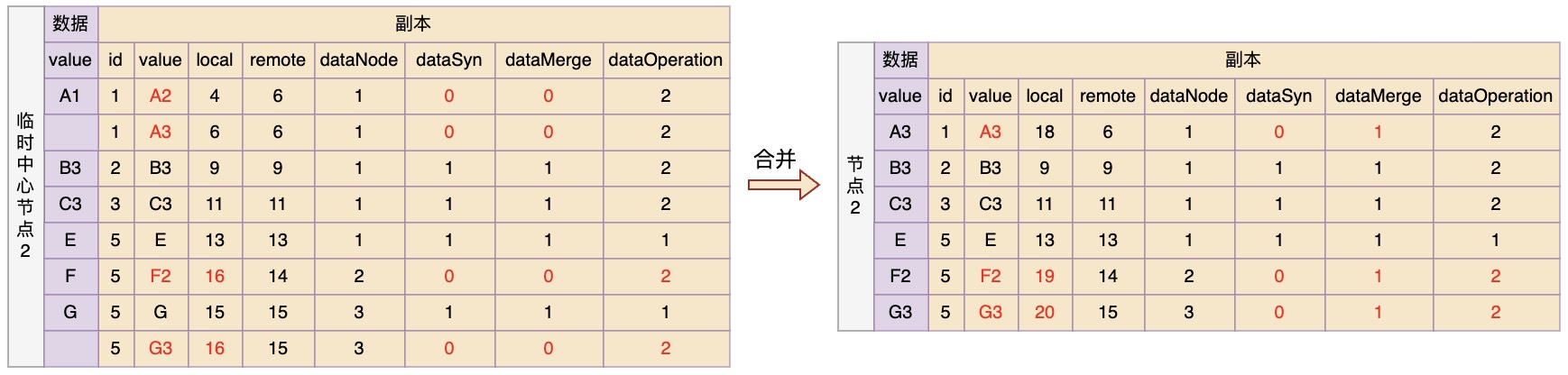
最后节点3拉取合并后的变更进行更新,同样复用之前的规则

中心节点恢复
如果出现断连的中心节点再次恢复了,那么就让临时中心节点将dataSyn=0的变更推送给它进行合并,然后再按照之前的规则进行拉取即可。
现在假设节点1又恢复了连接,那么让节点2向其推送变更
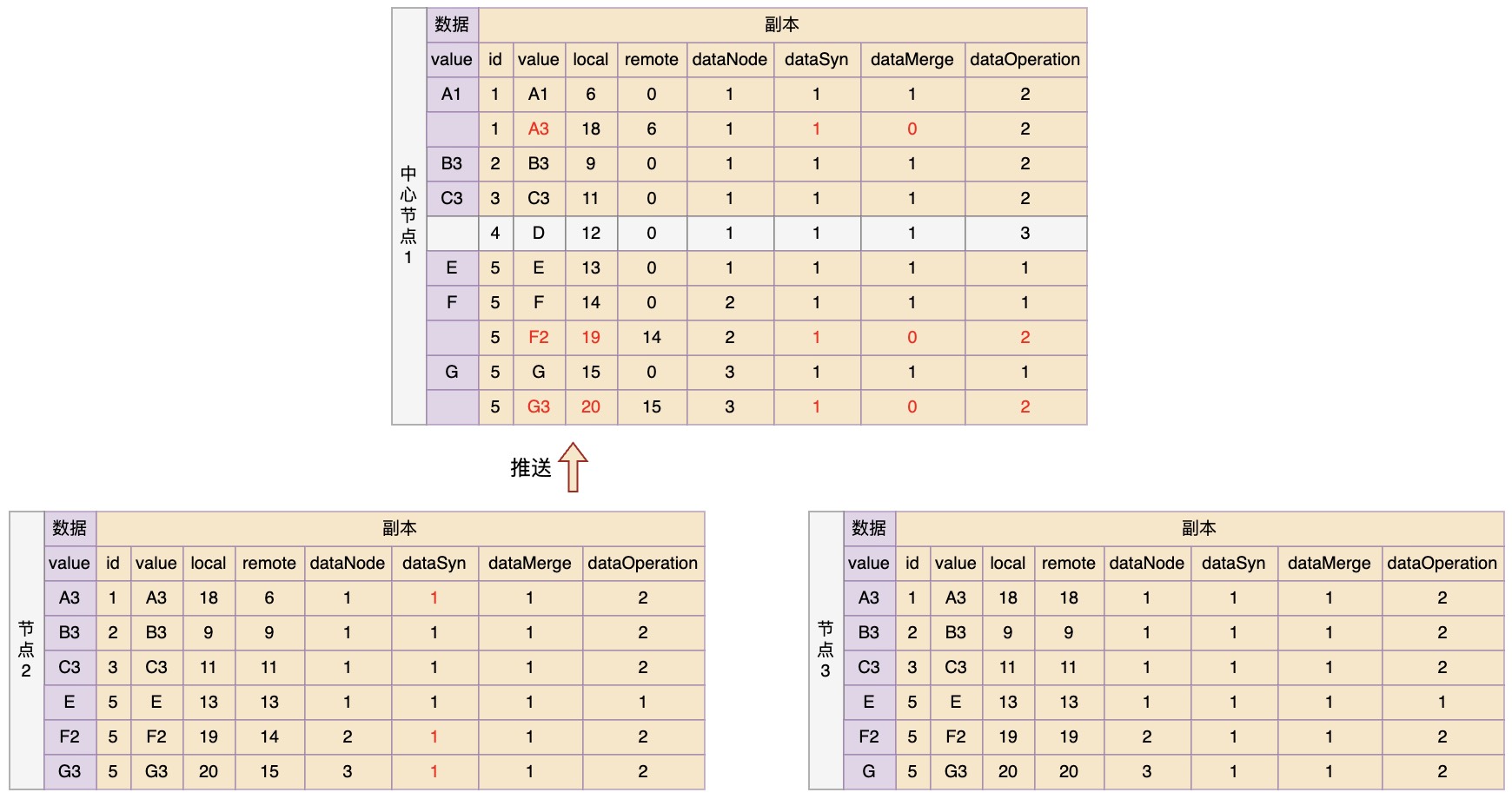
然后在中心节点1中进行变更合并
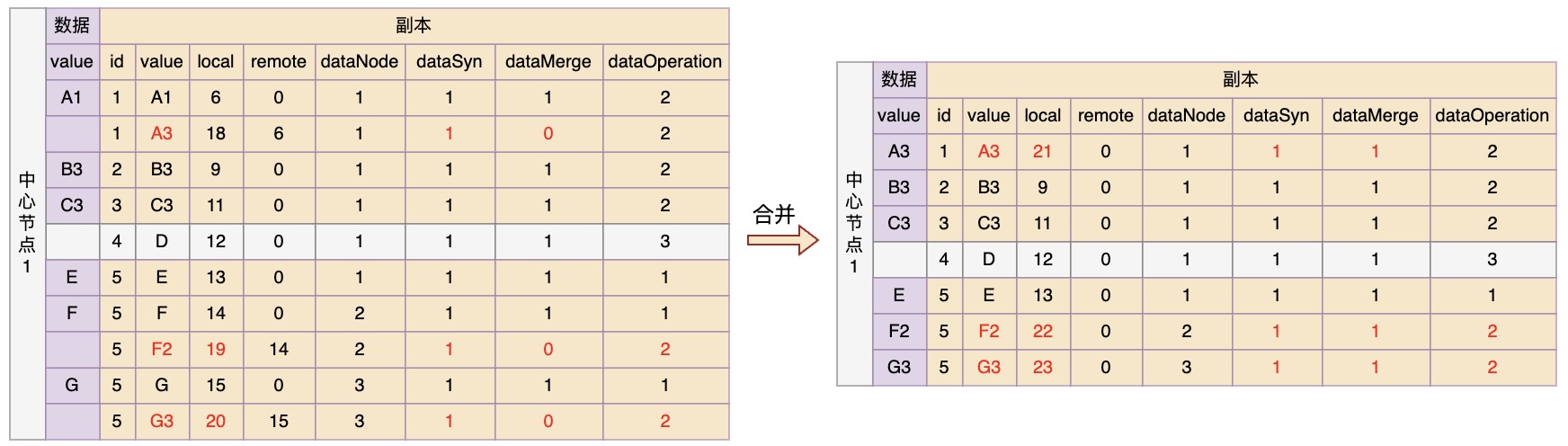
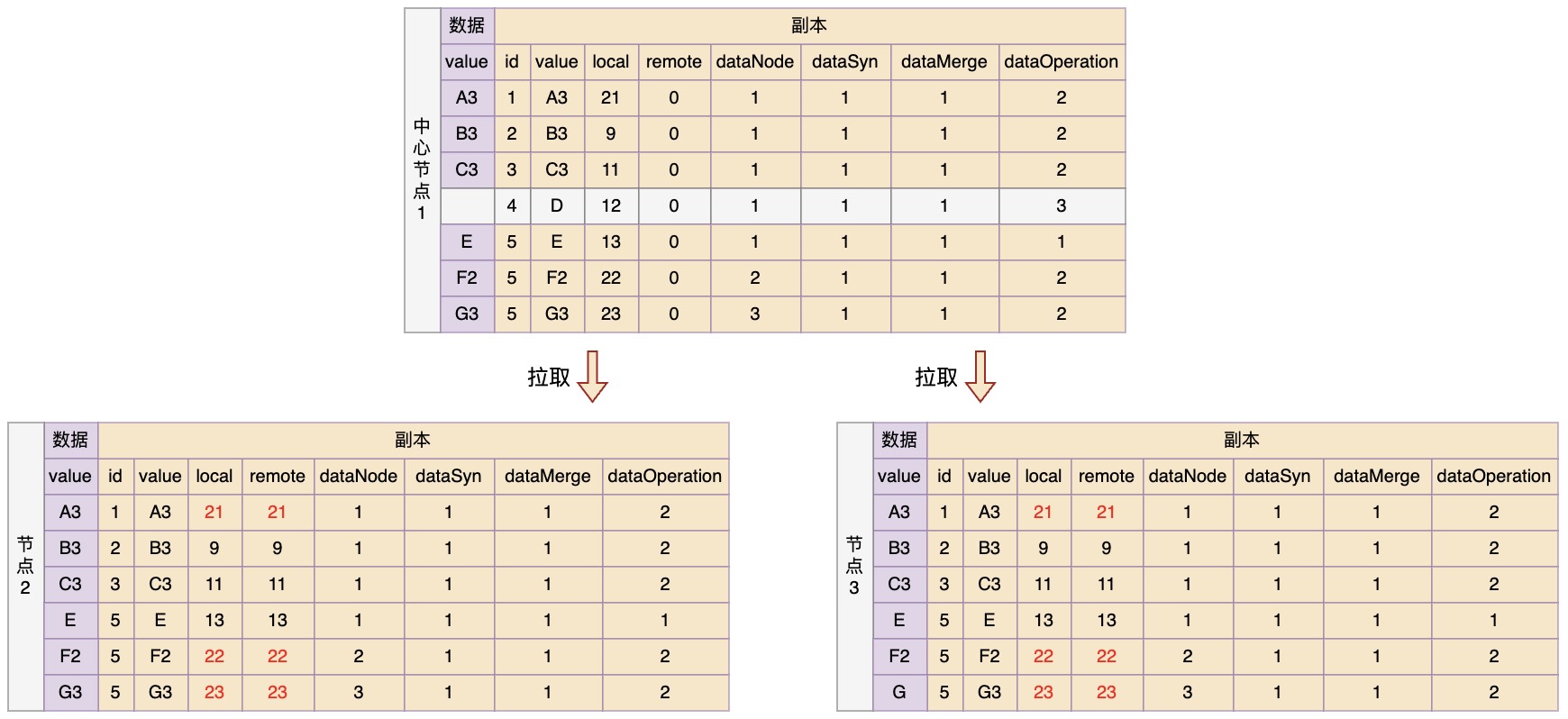
最后,节点2和3再进行拉取更新,那么最终所有节点的数据和副本又恢复到了一致的状态
总结
可以看到,通过一些步骤,以及添加一些辅助信息,并约定这些辅助信息在步骤中的变化规则,我们能够做到让不同节点中的数据变化进行同步。即使当节点间出现了网络断连的情况,也能在断开的子网络中进行数据变更同步,并且在中心节点恢复连接之后不会丢失之前没有同步到的变更记录,这样我们也能应对出现网络分区的场景,比如下面这样
参考: